![[AWS Lambda+Python]ライブ更新情報を自動ツイートするツールを作った話](/thumb/livebot-thumb.png)
背景
私の好きなコンテンツの音楽ライブの最新情報はtwitterとHPで発信されることが多くて、今まではtwitterにて情報を確認していました。
しかし、音楽ライブ以外の情報に興味がないため、音楽ライブ以外の情報も発信されるtwitterで情報を追うのが非効率だと感じていました。
かといって、いちいちHPを確認しに行くのも非効率なため、Python+AWSで自動で定期的にHPの情報を取得して、更新があれば更新分の情報をツイートするツールを作成しました。
AWS部分をTerraformでコード化しました。詳細は以下記事に記載しております。
![[Terraform+AWS]Pythonツールのインフラ(AWS)をTerraformで構築した話](https://soramania.com/thumb/terraform-arch-thumb.png) IaCとして注目されているTerraformについて、今更ながらインフラエンジニアとして興味があって触ってみようと言うのが動機です。以前作成したツールのインフラ部分をAWSのGUIから作成しており、Terraformで構築し直してみるというのが目標です。
IaCとして注目されているTerraformについて、今更ながらインフラエンジニアとして興味があって触ってみようと言うのが動機です。以前作成したツールのインフラ部分をAWSのGUIから作成しており、Terraformで構築し直してみるというのが目標です。
制作したもの・構成
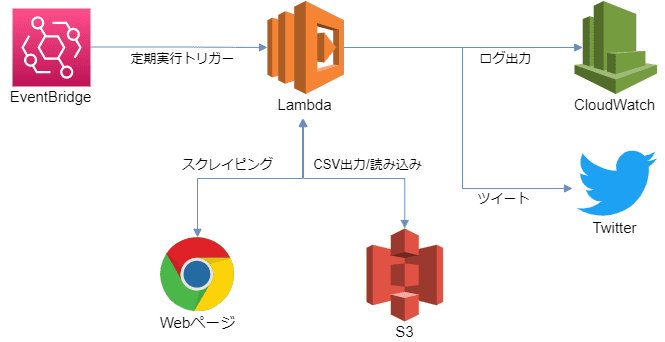
EventBridge:定期実行のトリガーを発出する。(現状1日2回としている。)
Lambda:EventBridgeのトリガーを受けてPython実行する。
HPからのスクレイピング、取得した情報をcsv化してS3に格納、S3に格納されているCSVの読み込み/比較、TwitterAPIからの更新分のツイート等を行う。
CloudWatch:Lambdaの実行ログを管理する。
S3:スクレイピングした情報をcsv化して格納する。
IAM(上記図にはなし):LambdaからAWSサービスへアクセスする際のロールを管理する。
twitter:TwitterAPIを利用して、音楽ライブイベント情報の更新分をツイートする。
更新カテゴリ(新情報や開催日時決定とか)、ライブタイトル、開催日時、場所、ライブ情報のURLをツイートします。
環境
- ローカル環境:Windows10 Home(Core i5-8400)
- テスト環境:Docker Desktop(イメージ:amazon/aws-sam-cli-build-image-python3.8)
- 実行環境:AWS(Lambda(ランタイム:Python3.8))
テスト環境はローカル環境にDockerを入れて構築しましたが、AWSにてECSを使ったり、EC2にDockerを入れたりでも構築できます。
詳細は後述します。
今回はPython3.8にしていますが、Python3.9用のDockerイメージもあると思うので、コーディング時や構築時から考慮しておけばPython3.9でも可能です。
ソースコード(Python)
プログラム内の処理の流れ
- HPからライブイベント情報を取得(スクレイピング)
- 取得した情報とS3にある過去情報のCSVを読み込んで比較
- 差分があればTwitterAPI経由でツイート(差分がなければ以降は実行せず、最新csvは削除)
- S3上のCSVをリネーム
この後、それぞれの処理の詳細をコード付きで記載しますが、必要箇所を抜粋して掲載するため、そのままコピペで使えないものがあるかもしれないことはご了承ください。
HPからライブイベント情報を取得(スクレイピング)
対象のページからスクレイピングをします。
import requests
from bs4 import BeautifulSoup
#スクレイピング
url_sc = "https://bang-dream.com/events"
response = requests.get(url_sc)
soup = BeautifulSoup(response.text, "html.parser")
elems = soup.find_all('ul', attrs={"class": "liveEventList"})
#イベントごとにliで区切られているため、li箇所の抜き出し
events = elems[0].find_all("li")スクレイピングのやり方は、以下の本を参考にしました。

今回使用しているBeautifulSoupでのスクレイピングはもちろん、Seleniumでの自動入力やクローリング等も記載されており、スクレイピングする上で必要な知識はこの1冊で十分身に着くと思います。
Amazon Prime会員だと、Kindle版が無料で読めるのでお金をかけたくない人にもおすすめです。
ただし、Kindle版は読みにくい可能性もあるので、個人的にはペーパーブックで読むことをおすすめします。
上記参考書を読み進めるのがつらく、もう少し簡単な参考書を求める人は以下もおすすめです。

本屋で実際に読んでみましたが、図が多く読み進めやすいと思います。
取得した情報とS3にある過去情報のCSVを読み込んで比較
スクレイピングした情報をCSV化した後、S3に事前にスクレイピングして取得していた過去情報が記載されているCSVと、先ほど取得した最新情報を比較します。
無駄な処理を削減して処理効率化しました。以下コードも修正しております。
"~"が文字コードエラーで引っかかったため、utf-8からcp932に変更しました。
比較はPandasでデータフレームを使っています。
import pandas as pd
import boto3
import os
#S3バケット内でのファイル生成準備
s3 = boto3.resource('s3')
bucket_name = "バケット名"
s3_filename_old = '旧CSVのファイル名'
#S3バケット内の最新のCSVを読み込み
df_old_object = s3.Object(bucket_name, s3_filename_old)
body_in = df_old_object.get()['Body'].read().decode("cp932")
buffer_in = io.StringIO(body_in)
df_old = pd.read_csv(buffer_in, lineterminator='\n')
#スクレイピングした情報のデータフレーム化
df_new = pd.DataFrame(event_list[1:], columns=event_list[0])
#新情報を抜き出すためのリストの定義
df_old_comv = df_old.copy()
df_new_comv = df_new.copy()
#比較結果リストの作成(True,False判定)
df_comp = (df_old_comv==df_new_comv))
#新情報の番号抽出・新情報の抜出後の比較リスト作成(True,False判定)
#新情報が何番目の行かをリスト化
new_line_num_list = []
new_quantity = 0
for row in range(10):
row = row - len(new_line_num_list)
#タイトル・URL・日付が全て異なっている場合は新情報とみなす
if ((~(df_comp.iat[row, 0])) and (~(df_comp.iat[row, 1])) and (~(df_comp.iat[row, 2]))):
#新情報の行番号をリストに保存
new_line_num_list.append(row + len(new_line_num_list))
df_new_comv = df_new_comv.drop(df_new_comv.index[row])
df_old_comv = df_old_comv.drop(df_old_comv.index[-1])
df_new_comv = df_new_comv.reset_index(drop=True)
df_old_comv = df_old_comv.reset_index(drop=True)
df_comp = (df_old_comv == df_new_comv)
new_quantity += 1
#更新カテゴリ入れ(更新された情報に応じてツイート冒頭の記載を変えるため)
for row in range(10 - new_quantity):
update_category = "None"
if ~(df_comp.iat[row, 2]):
update_category = "ライブ日程決定"
elif ~(df_comp.iat[row, 3]):
update_category = "ライブ開催場所決定"
elif ~(df_comp.iat[row, 0]):
update_category = "ライブタイトル決定"
elif (~(df_comp.iat[row, 0])) or (~(df_comp.iat[row, 2])) or (~(df_comp.iat[row, 3])) or (~(df_comp.iat[row, 4])):
update_category = "ライブ情報更新"
df_comp.iat[row, 5] = update_category差分があればTwitterAPI経由でツイート
比較したCSVに差分があれば、ツイートを作成します。
ツイートは、tweepyでオブジェクトを作成して、TwitterAPI経由で実行します。
コード上のコメントに追記していますが、TwitterAPIの鍵は直接記載せずにLambdaの環境変数にて設定してください。
直接書いてコードを公開したら悪用される可能性があるので注意してください。
import tweepy
#ツイート内容を入れる配列を作成
tweet_array = []
#新情報のツイート内容作成
for row in new_line_num_list:
text = "【新情報】\n{title}\n開催日時:{date}\n場所:{place}\n{URL}"
tweet_array.append(text.format(title=df_new.iat[row,0], date=df_new.iat[row,2], place=df_new.iat[row,3], URL=df_new.iat[row,1]))
#情報更新のツイート内容作成
for row in range(10 - new_quantity):
if df_comp.iat[row,5] != "None":
text = "【{update_category}】\n{title}\n開催日時:{date}\n場所:{place}\n{URL}"
tweet_array.append(text.format(update_category=df_comp.iat[row,5], title=df_new_comv.iat[row,0], date=df_new_comv.iat[row,2], place=df_new_comv.iat[row,3], URL=df_new_comv.iat[row,1]))
#更新があれば自動ツイートとcsvリネーム処理を実行
#TwitterAPIの鍵はLambda上で定義したものを経由して記載(直接書くのはダメ!)
if (new_quantity != 0) or (~(df_old_comv.equals(df_new_comv))):
twitter_consumer_key = os.environ['CONSUMER_KEY']
twitter_consumer_secret = os.environ['CONSUMER_KEY_SECRET']
twitter_access_token = os.environ['ACCESS_TOKEN_KEY']
twitter_access_token_secret = os.environ['ACCESS_TOKEN_KEY_SECRET']
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(twitter_consumer_key, twitter_consumer_secret)
auth.set_access_token(twitter_access_token, twitter_access_token_secret)
api = tweepy.API(auth)
#情報のツイート
for tweet in enumerate(tweet_array):
# ツイートを投稿
api.update_status(tweet[1])S3上の旧CSVのリネーム、最新情報のCSV化+S3へのアップロード
後処理として、旧CSVを実行日時を含んだ名前にリネーム、最新情報をCSV化してS3へアップロードします。
S3ではオブジェクトのリネームは出来ないため、変更後のファイル名でコピーした後にコピー元を削除する流れで実行します。
import datetime
import boto3
import os
#csv更新処理
#現在の日時と日付の文字列変換
dt_now = datetime.datetime.now()
d_today = datetime.date.today()
now_hour = str(dt_now.hour)
hour_zero = now_hour.zfill(2)
today = str(d_today)
#古いファイルの名前作成
old_csv = "旧CSVのファイル名-{day}-{hour}.csv"
old_csv_form = old_csv.format(day=today, hour=hour_zero)
#古いファイルを過去ファイルに移動
old_copy_to = '過去ファイル用のバケット名/' + old_csv_form
s3.Object(bucket_name, old_copy_to).copy_from(CopySource={'Bucket': bucket_name, 'Key': s3_filename_old})
s3.Object(bucket_name, s3_filename_old).delete()
#実行後の最新ファイルを次回比較のためにS3にアップロード
#一時利用ファイルパス
tmp_path = "/tmp/data.csv"
#CSV書き込み
with open(tmp_path, "w", encoding="cp932") as file:
writer = csv.writer(file, lineterminator="\n")
writer.writerows(event_list)
bucket = s3.Bucket(bucket_name)
bucket.upload_file(tmp_path, s3_filename_old)
#tmpファイルの削除
os.remove(tmp_path)テスト環境構築{#dev-env}
Dockerを使ってテスト環境を構築します。
Dockerを使ったことない方も心配しなくて大丈夫です。
私も本ツール開発と同じようなことをした際にDockerに関して初心者でしたが、以下の本で一通り学ぶことができました。
やっていることは単純なため、1日あれば最低限使えるようになると思います。

Kubernetesの知識は本ツールでは不要です。(個人開発規模ならあまり必要ないです。)
ローカルの場合
DockerのHPからDocker Desktopをインストールします。
私はWindowsで環境構築しましたが、MacでもLinuxでも可能です。
次に、Docker DesktopにLambdaのイメージをダウンロードします。
Lambdaと同等の環境のイメージがDockerHub上に公開されているので、そこからイメージを取得します。
ちなみに、Python3.9も上記リンクの末尾を3.9に変えれば見つかりました。
この後は、イメージからコンテナを作成してテスト環境は完成です。
AWSの場合
ローカル上にテスト環境を構築しても、そこまで動作が重くならず問題ないと思いますが、PCのスペックがあまりに低かったり、ローカル上に構築したくなかったりするなら、AWS上にも構築できます。
AWSにて環境構築する方法は大きく2つあって、1つはSAMを使用する方法、もう1つはECSやEC2でサーバを立てる方法です。
理想的にはSAMを使用する方法だと思います。
ただし、Dockerの知識を深めたいこともあって今回は使用しませんでした。
EC2やECSを使用する方法は、GUI上で操作して作成していくだけのため簡単です。
EC2とECSの違いについて簡単に説明すると、EC2はサーバ、ECSはEC2やForgate上にコンテナを作成できるようにしたものを管理できるサービスです。
そのため、ECSにて構築環境にEC2を選択した場合は、EC2にDockerがインストールされたものを構築するため、結局はEC2が構築されます。
EC2はサーバのため、Dockerを使用する場合は、別途Dockerをインストールする必要があります。
ECSならDockerは既にインストールされている状態、EC2ならDockerをインストールした状態で、ローカル上に構築した時と同様に、Lambdaのイメージを取得してくれば、テスト用のコンテナが作成できます。
実行環境構築(AWS)
AWS CLFを取得するメリット
AWS部分をTerraformでコード化しました。詳細は以下記事に記載しております。
IaCとして注目されているTerraformについて、今更ながらインフラエンジニアとして興味があって触ってみようと言うのが動機です。以前作成したツールのインフラ部分をAWSのGUIから作成しており、Terraformで構築し直してみるというのが目標です。
使用するサービスは、S3・Lambda・EventBridge・CloudWatchの4つです。
私の場合、AWSに関する知識は、AWSの認定試験であるSAAやSOA・DVA等を取得したこともあり、基本的な知識は持っていました。
AWSを触ったことがない方は、Udemyの動画教材である「【SAA-C03版】これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座」がおすすめです。

SAAの動画教材ではありますが、ハンズオン形式で学ぶことでサービスごとにAWSの操作がわかり理解が深まりました。
今回、Lambdaを使う上で、Lambdaの詳細な部分まで知りたかったため、上記とは別に以下の本を参考にしました。
Lambdaを使う上で必要な知識は全て詰め込まれていると言えるほど、詳細に書かれています。

ストレージ(S3)の準備
プログラム実行時に作成/読み込みするCSVを配置するためのバケットを作成します。
バケットの作り方は、GUI上で見ればわかると思うので、説明は割愛します。
実行環境(Lambda)の設定
Lambdaの作成
Pythonを実行するためのLambdaを作成します。
「Lambda」⇒「関数の作成」⇒「一から作成(ランタイムはPython3.8)」で新規作成します。
Lambdaにソースコードをアップ
Lambdaにソースコードをアップロードします。
アップロード方法は、直接アップロードする方法とS3経由でアップロードする方法があります。
アップロードするファイルはzipファイルのため、ライブラリ含めてDockerコンテナ上(Linux上)でzip化してください。(Windows等でzip化するとCライブラリ関連のエラーが出ます。)
今回のツールのように、S3にアクセスする必要がある場合は、Lambdaの設定にアクセス権限があるので、そこからアクセスに必要なロールを割り当ててください。
環境変数の設定
TwitterAPIキー等の環境変数を設定します。
Lambdaの設定に環境変数があります。
TwitterAPIはコードに直接書くとGithub等で公開した際に悪用されるので、環境変数等で定義してコードに直接書かないようにしてください。
キー管理としてSecrets Mangerを使用することもできますが、無料枠がないため私は使用しませんでした。
テスト実行
実際運用の前にテストをします。
Lambdaのテストから実行できます。
定期実行(EventBridge)の設定
定期実行するために、Lambdaに実行指示を出すEventBridgeのルールをします。
EventBridgeを選択してルールを作成することもできますが、Lambdaの画面の「トリガーを追加」から追加することができます。
cron式の記載方法がわからない方は、EventBridgeからルールを作成するとわかりやすいです。
cronではUTC(協定世界時)での指定となるため、9時間のずれがあることに注意してください。
ログ取得(CloudWatch)の設定
実行ログを取得するため、CloudWatchの設定をします。
Lambdaのモニタリングからログを有効化するだけで、ログが蓄積されるようになります。
LambdaにCloudWatchにアクセスするためのロールを設定することを忘れないようにしてください。(私はこれを忘れていて数日間ログが取れてなかったです。)
プログラム実行
ここまでの設定が終わっていれば、EventBridgeで定期実行のトリガーが走ったときに実行されます。
エラーが出ないかの確認はテストで確認しておいてください。
つまずいたポイント
TwitterAPIでのエラー
⇒アカウントレベルを上げることで解消しました。参考にしたサイトは後述します。ライブラリ起因でのエラー
⇒Lambdaの環境と同じ環境でライブラリをインストールして、zip化もその環境上(Linux上)で実施する必要がありました。Windows上でzip化するとC言語ライブラリの影響でエラーになります。
参考にしたサイト
AWS Lambdaで列車運行情報を定期的にLINEへ通知してみた【Python】
⇒似たようなことをやっていて参考にさせていただきました。AWS lambda を使ってWebスクレイピングしたった
⇒Lambdaの関数作成やロール追加等、画面付きで記載されています。(私は面倒で簡略化して書きました。)Lambda Python3.6でTweetしてみた[with Serverless Framework]
⇒TwitterAPI keyの取得等も画面キャプチャ付きで記載されています。【Python×Twitter】検索ツイートのデータ取得・分析|APIとtweepy活用による自動運用アプリ開発支援
⇒tweepyの細かい使い方が記載されています。tweepy + Twitter API V2でツイート
⇒TwitterAPI周りでエラーが出たときに参考にさせていただきました。【Python】boto3でS3ファイル操作まとめ
⇒S3の操作で参考にさせていただきました。
最後に
今回は「[AWS Lambda+Python]ライブ更新情報を自動ツイートするツールを作った話」を紹介しましたが、いかがだったでしょうか?
本ブログでは、ゲーム開発や心理学、IT全般、資格取得の最短勉強法についての情報を発信しています。
今後もコンテンツを追加していく予定なので、他にも気になる記事があればぜひご覧いただけると嬉しいです。
関連記事
 AWS SAA(Solutions Architect Associate)に2週間という短期間で資格取得した合格体験記であり、勉強方法も再現性があると考えております。AWS SAAを取得したい方は参考にしていただけると幸いです。
AWS SAA(Solutions Architect Associate)に2週間という短期間で資格取得した合格体験記であり、勉強方法も再現性があると考えております。AWS SAAを取得したい方は参考にしていただけると幸いです。
 本記事は、AWS SOA(SysOpsアドミニストレータ)に2週間という短期間で資格取得した合格体験記であり、勉強方法も再現性があると考えております。AWS SOAを取得したい方は参考にしていただけると幸いです。
本記事は、AWS SOA(SysOpsアドミニストレータ)に2週間という短期間で資格取得した合格体験記であり、勉強方法も再現性があると考えております。AWS SOAを取得したい方は参考にしていただけると幸いです。
記事に対する感想や記事のリクエストについては、プロフィールの連絡先からいただけると幸いです。
この記事をシェア